Background
Sentiment analysis has emerged as a leading technique to automatically identify affective information within texts. In sentiment analysis, affective states are generally represented using either categorical or dimensional approaches (Calvo and Kim, 2013). The categorical approach represents affective states as several discrete classes (e.g., positive, negative, neutral), while the dimensional approach represents affective states as continuous numerical values on multiple dimensions, such as valence-arousal (VA) space (Russell, 1980), as shown in Fig. 1. The valence represents the degree of pleasant and unpleasant (or positive and negative) feelings, and the arousal represents the degree of excitement and calm. Based on this two-dimensional representation, any affective state can be represented as a point in the VA coordinate plane by determining the degrees of valence and arousal of given words (Wei et al., 2011; Malandrakis et al., 2013; Wang et al., 2016; Du and Zhang, 2016; Wu et la., 2017; Yu et al., 2020; Deng et al., 2022) or texts (Kim et al., 2010; Paltoglou et al, 2013; Goel et la., 2017; Zhu et al., 2019; Wang et al., 2019; 2020; Deng et al., 2023; Lin et al., 2024).
The first dimensional sentiment analysis (DSA) task for Chinese words (Yu et al., 20216) was organized at the IALP 2016 conference. The second edition of DSA task was organized at the IJCNLP 2017 conference to include both Chinese words and phrases (Yu et al., 2017). The third edition was organized at the ROCLING 2021 conference to explore the sentence-level dimensional sentiment analysis task on educational texts (students’ self-evaluated comments) (Yu et al., 2021). The fourth edition of DSA task was orginized at the ROCLING 2025 conferenceto to analyze medical multi-sentence texts (Lee et al., 2025). This year, we organize the fifth edition of the DSA shared task, which focuses on dimensional sentiment prediction for texts reflecting the feelings, daily experiences, and psychological states of new immigrants.
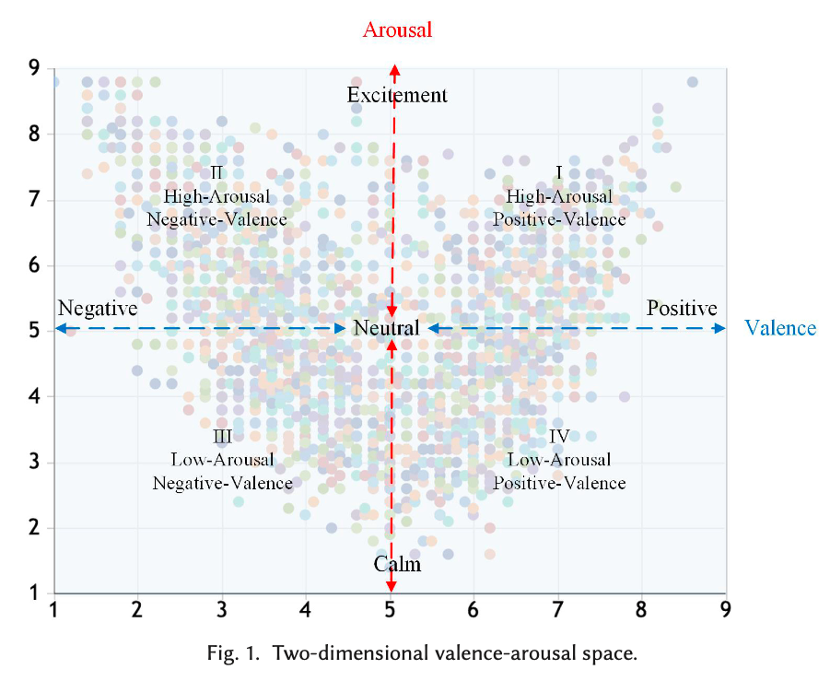
Figure 1: Valence-Arousal Space